2016.07.21
レポート
IoT,AI時代の知的財産権(2016年7月21日 第58回JIPDECセミナー)
IoT,AI時代の知的財産権
~人工知能による創作と、「次世代知財」報告書を題材に
骨董通り法律事務所 代表
弁護士 福井 健策 氏

印刷用
人工知能と「創作」の現状

近年、人工知能(AI)が、人間の独壇場とされていた領域に次々と進出してきている。今後10~20年以内にコンピュータやロボットに仕事を奪われそうな職種・奪われそうにない職種の予測では、クリエイター系の職種は代替される確率が比較的低いとされた。創作性というのは人間こそが持っているものだと言われている。しかし、本当にそうだろうか。故スティーブ・ジョブズは、「創造性は物事の”結びつけ”に過ぎない」と述べている。
AI創作物について考えると、たとえば音楽であれば、質の向上だけでなくその創作スピードがかなり速まっているし、文章であれば、米AP通信社がスポーツ記事や企業業績の配信にAIを利用するなど、実務への利用も進んでいる。この他にも、写真や映像、バーチャルアイドルなど、さまざまな場面でAIの進出が盛んであり、ボーカロイドのコンサートに数万人の観客が熱狂するなどAI創作物に対する人間の感情面での反応も生まれている。
人工知能の創作は著作物か
こうしたAI創作物は、著作物にあたるのだろうか。わが国の現行著作権法上、著作物は「思想・感情の創作的な表現」であると定義されている。1993年の文化審議会第9小委員会では、「人がコンピュータを道具として使った場合に(のみ)著作物たり得る」(著作者は基本的にユーザー)と結論付けられたが、これは、米国78年CONTU、ユネスコ等82年勧告が出した「創作過程において、人の創造的寄与が必要」という見解と同じ方向性である。一方英国では、1988年法において、「人格権与えず」「保護期間は創作から50年」「著作者はnecessary arrangementをした者」という条件を付しつつ、完全コンピュータ創作(CGW)は著作物であると認めている(同法178条)。
IoT、AIをめぐる知財の論点
内閣知的財産戦略本部「次世代知財システム検討委員会」やその後の論議では、AI生成物に著作権が認められるかということだけではなく、過程にある各種データやプログラムの保護に関するさまざまな課題について議論されている。(図)
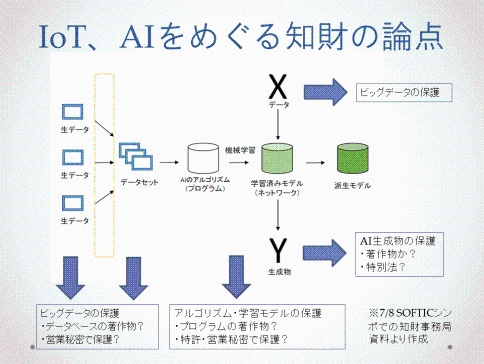
AIの学習においては「生データ」だけでなく「データセット」の独自性が肝となる。日本では、構成に独自性があればそのデータベース全体が著作物となるとされてきたが、最近ではデータベースの生成自体が機械的に行われており、従来の考え方ではこうした自動生成のデータベースは必ずしも保護されない。別の手段として、不正競争防止法における営業秘密として扱うことも考えられるが、たとえば広く公開されている3Dプリンタのデータなどはその対象範囲から漏れてしまう。AIの命ともいえる学習済みモデル(ネットワーク)はプログラムの著作物として守られ得るが、多様な要素の組み合わせによってAIのビジネスやAIによる創作が行われているので、どこに知的財産権を認めるかそれぞれ問題になる。現在の通説では、アルゴリズム・学習モデルは知的財産法に守られ、ビッグデータはケース・バイ・ケースで判断され、AI生成物は保護されないとなりそうである。
そのコンテンツは誰が握るのか
AI生成物が仮に著作物だとすると、英国1988年著作権法で“necessary arrangement”をした者が権利者とされているように、開発・運用企業、すなわち元となったビッグデータを握っている企業、グーグルやアップルなどのプラットフォーマーといわれる企業が著作権者になるのではないかと考えられる。
プラットフォーマーには、AIが作り出すまでもなく行動履歴や検索語など膨大なコンテンツが集まり、これらをAIに学習させることができるのである。また、グーグルが提供するYouTubeの利用規約には、“YouTubeにアップされた動画はグーグルが自由に使える”とあり、アップルもアマゾンも同様に自身のプラットフォーム上に集まったコンテンツを自由に使用できる。また彼らは、そうして得たアルゴリズムによるランキング作成やリコメンドを通じて「知」の序列化まで行っている。さらに、彼らはグローバルに活動しており、特定の国の法制度に縛られない超国家的な存在として、情報のルールメークが可能になっている。
こうした米国系企業を中心としたプラットフォーム寡占に危機感を募らせたEUでは、各種の課税や調査を行ったり、ヨーロッパ中の美術館や博物館の情報を集めた歴史・文化に関する独自プラットフォーム(「Europeana」)を作ったり、コンテンツを発信しやすくするよう著作権リフォーム案の検討を行うなど、さまざまな取組みを行っている。
変容する著作権の前提
昭和45年に成立したわが国の現行著作権法は、現在のような膨大なコンテンツ量は想定しておらず、「権利者を探して許可を得てから利用する」というオプトインの考え方に基づいている。グーグルやアップルなどの米国企業は「フェア・ユース制度」などをテコにギガコンテンツ時代に突入したが、わが国で大規模コンテンツを扱う際には必ず著作権法が壁になる。また今後もコンテンツが爆発的に増え続けることで、コンテンツ自体の価格破壊が進むことも考えられ、コンテンツの非代替性を前提とする少数囲い込みのビジネスモデルと、それを支える「コピー・ライト」制度が限界に達しているように思われる。
一方、膨大なコンテンツから、ユーザーが求めるコンテンツにうまく結びつけるためのデータ解析やマーケティングが重視されるようになっていることや、創作物の鑑賞ではなく体験・参加をすることに価値がおかれる「ライブシフト」が起きていることなどから、これまでのようなコンテンツそのものの保護ではなく、たとえばコンテンツを生み出すAIを作るためのビッグデータへの投資や新たなビジネスモデルなど、投資・ビジネスモデル・創作の場の保護が求められるように変化してきているのではないだろうか。
著作権はこれからどのように変わっていくのか
私たちの豊かな創造と情報へのアクセスを守るために、著作権をどうリフォームしていくかが世界的な課題である。日本でもこうした議論を行っており、2016年4月に内閣知的財産戦略本部から発表された「次世代知財システム委員会」の報告書では、権利処理のコスト低下につながる制度変更、新たな情報財の扱い、国境を越えた海賊版などの対策、という三点を指摘している。
このうち、権利処理のコストを低下については、情報発信を容易化することがその目的である。権利情報の集中管理や、拡大集中許諾、権利者不明の「孤児著作物」対策などによって許諾を取りやすくし、どうしても許諾を取るのが現実的でない場面では例外的に許諾なしでも使えるようにする、といった内容を想定している。
知的財産権は、いわば情報の独占権である。新しいコンテンツが生まれたとき、情報を独占するメリットと、独占されて囲い込まれるデメリットのどちらが大きいのかを比較し、メリットがデメリットを越えるときに初めて知的財産権で保護するかどうかという議論となる。またその際には、知的財産権ではなく、契約や別の法律、技術など、より実効性のある優れた代替手段はないか、という議論が大切である。